
Еще пару лет назад мы спорили, заменит ли ИИ программиста. Сегодня мы спорим, какой именно ИИ лучше справляется с рефакторингом легаси-кода. Нейросети перестали быть игрушкой для генерации стишков и превратились в полноценный рабочий инструмент.
Вы уже наверняка привыкли, что GPT пишет за вас тесты, а Claude подкидывает идеи для архитектуры.
Но рынок перенасыщен. Модели выходят каждую неделю: вчера все обсуждали o1, сегодня в топах GPT-5.2, а завтра Google выкатывает очередную Gemini 3. Держать всё в голове невозможно, а выбирать наугад — дорого и неэффективно. Разбираемся, как айтишнику не утонуть в этом океане токенов и найти то, что реально ускорит работу.
Как выбрать нейросеть

Первое, что нужно понять: не существует «самой лучшей» модели. Есть модель, идеально заточенная под ваши нужды. Вы же не будете использовать молоток для закручивания шурупов? С нейросетями та же история.
Задайте себе три вопроса:
- Что я буду делать? Писать код, анализировать документы, общаться с клиентами, генерировать изображения по ТЗ?
- Сколько я готов платить? Бюджет — решающий фактор. Крутая модель с гигантским контекстом может оказаться золотой, когда вы отправляете ей тонны данных ежедневно.
- Что для меня важнее: скорость или глубина? Нужен быстрый ответ на простой вопрос или сложный анализ с многоэтапными рассуждениями?
И здесь наступает момент истины. Ручной перебор всех моделей — путь в никуда. Тратить рабочие дни на изучение документации к каждому API, сравнение цен и запуск собственных тестов — непозволительная роскошь. Надо действовать умнее.
Используем сервис сравнения языковых моделей
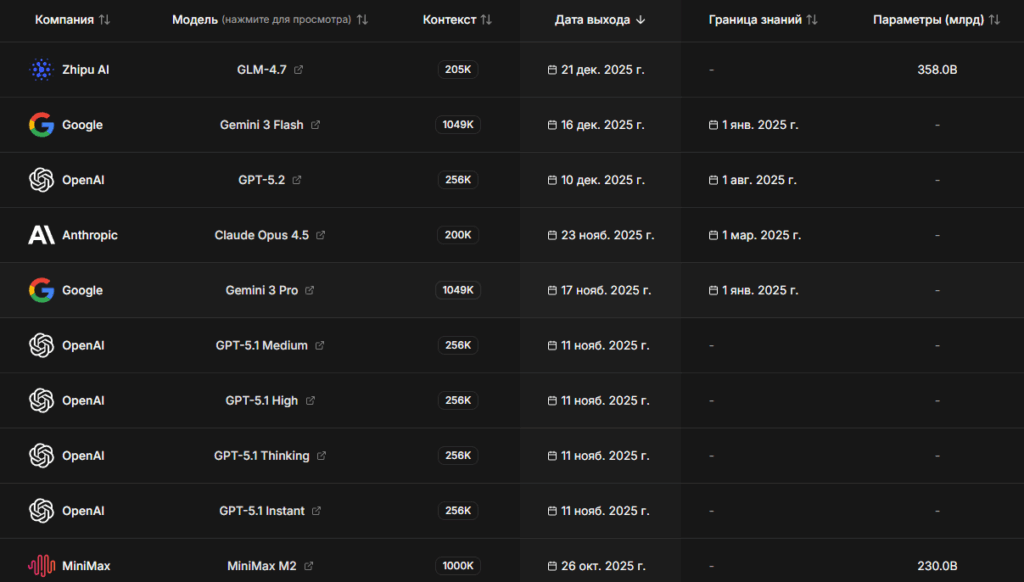
На сервисе AI-Stat нейросети разложены по полочкам. Здесь можно за пару минут сравнить ИИ и понять, какие модели сейчас реально сильнее, а какие просто громко звучат в новостях.
Вы смотрите рейтинг языковых моделей, фильтруете по нужным параметрам — например, большой контекст или мультимодальность — и сразу видите:
- результаты ключевых бенчмарков: от HumanEval до GPQA и SWE-Bench;
- стоимость входных и выходных токенов;
- размер контекстного окна и границу знаний;
- реальные данные по скорости генерации.

Отдельный плюс — рейтинги по конкретным сценариям. И всё это регулярно обновляется.
Нужно выбрать модель для кода? Есть отдельный лидерборд.
Важен tool calling для агентов и автоматизации? Пожалуйста, рейтинг на основе Tau2 и ComplexFuncBench с понятным процентом надёжности.
Итог
Айтишнику сегодня выгодно относиться к нейросетям прагматично. Не как к магии и не как к игрушке, а как к инструменту с характеристиками, ограничениями и ценой. Правильный выбор модели экономит часы работы, снижает количество ошибок и напрямую влияет на результат.
Вместо того чтобы гадать или полагаться на хайп, проще открыть сервис сравнения, посмотреть реальные метрики и выбрать нейросеть под конкретную задачу. Это ровно тот случай, когда несколько минут анализа окупаются уже в первый рабочий день.

Статический и динамический IP: в чем разница и как выбрать
Как объединить заявки, обслуживание оборудования и работу выездных сотрудников в единой FSM-системе

Как обновить ИТ-систему без остановки бизнеса: эволюция вместо революции

Эволюция защиты конечных точек: зачем бизнесу решения класса EDR и как их внедрить
